和具有相同的增长速度。
是的。
斐波那契数列的定义为:, , , =2, 3, …。用递归函数计算的时间复杂度是。
算法分析的两个主要方面是时间复杂度和空间复杂度的分析。
算法可以没有输入,但是必须有输出。
时间复杂度是根据算法写成的程序在执行时耗费时间的长度,往往与输入数据的规模有关。
空间复杂度是根据算法写成的程序在执行时占用存储单元的长度,往往与输入数据的规模有关。
递归程序往往简洁易懂,但占用较大空间。递归层数过大会造成系统堆栈溢出。
选择排序的时间复杂度是O()。
在长度为的顺序表中查找最大元素,平均时间复杂度是。
顺序存储方式只能用于存储线性结构。
在顺序表中取出第i个元素所花费的时间与i成正比。
顺序存储的线性表可以随机存取。
顺序存储结构的主要缺点是不利于插入或删除操作。
顺序表中逻辑上相邻的元素,其物理位置也一定相邻。
顺序存储的线性表可以随机存取。
顺序存储方式插入和删除时效率太低,因此它不如链式存储方式好。
链表是采用链式存储结构的线性表,进行插入、删除操作时,在链表中比在顺序存储结构中效率高。
在顺序表中,逻辑上相邻的元素,其物理位置必定相邻。
顺序存储设计时,存储单元的地址一定连续。
若用链表来表示一个线性表,则表中元素的地址一定是连续的。
将长度分别为m,n的两个单链表合并为一个单链表的时间复杂度为O(m+n)。
取线性表的第i个元素的时间同i的大小有关。
链表的每个结点都恰好有一个指针。
线性表的顺序存储表示优于链式存储表示。
在具有头结点的链式存储结构中,头指针指向链表中的第一个元素结点。
循环链表不是线性表。
带头结点的单循环链表中,任一结点的后继结点的指针域均不空。
在单链表中,逻辑上相邻的元素,其物理位置必定相邻。
对单链表来说,只有从头结点开始才能访问到表中所有结点。
栈是一种对进栈、出栈操作总次数做了限制的线性表。
栈是先进先出的线性表。
栈是一种特殊的线性表,它的插入和删除操作都是在表的同一端进行。 ~@
栈结构不会出现溢出现象。 ~@
序列{1,2,3,4,5}依次入栈,则不可能得到{3,4,1,2,5}的出栈序列。
栈是一种先进先出的线性表。
栈结构不会出现溢出现象。
链栈的插入在栈顶,删除在栈底。
若元素x,y,z依次入栈,出栈可任意,则不可能出现x,y,z的出栈顺序。
堆栈适合解决处理顺序与输入顺序相反的问题。
队列结构的顺序存储会产生假溢出现象。
队列中允许插入的一端叫队头,允许删除的一端叫队尾。
可以通过少用一个存储空间的方法解决循环队列假溢出现象。
循环队列也存在空间溢出的问题。
队列的特性
队列是后进先出的线性表。
队列适合解决处理顺序与输入顺序相反的问题。
队列适合解决处理顺序与输入顺序相同的问题。
不论是入队列操作还是入栈操作,在顺序存储结构上都需要考虑"溢出"情况。
队列中允许插入的一端叫队头,允许删除的一端叫队尾。 ~@
队列结构的顺序存储会产生假溢出现象。 ~@
将一棵完全二叉树存于数组中(根结点的下标为1)。则下标为23和24的两个结点是兄弟。
完全二叉树中,若一个结点没有左孩子,则它必是树叶。
完全二叉树的存储结构通常采用顺序存储结构。
一棵有9层结点的完全二叉树(层次从1开始计数),至少有255个结点。
一棵有9层结点的完全二叉树(层次从1开始计数),至少有256个结点。
一棵有9层结点的完全二叉树(层次从1开始计数),至少有512个结点。
完全二叉树一定存在度为1的结点。
完全二叉树中,若一个结点没有左孩子,则它必是树叶。
完全二叉树存储在数组A中,A[1..10]的元素值为{1,11,21,31,41,51,61,71,81,91},则元素51的双亲是21。
从形态上看,AVL树是完全二叉树。
若一个有向图无环,则它一定有唯一的拓扑序列。
连通分量是无向图中的极小连通子图。
关于图的遍历
图的广度优先遍历相当于二叉树的先序遍历。
邻接矩阵作为有向图的存储结构,则某顶点的度就是该顶点所在列的非零元素的个数。
有50个顶点的无向图,其最小生成树有51条边。
图是表示一对一关系的数据结构。
图是表示多对多关系的数据结构。
若无向图G有n个顶点(n > 1)和n-1条边但不是树,则G必定不是连通图。
若无向图G有n个顶点(n > 1)和n-1条边但不是树,则G必定有环。
图的广度优先遍历需要借助的数据结构是堆栈
在散列中,函数“插入”和“查找”具有同样的时间复杂度。
哈希函数的选取平方取中法最好。
哈希表的结点中只包含数据元素自身的信息,不包含任何指针。
在散列表中,所谓同义词就是具有相同散列地址的两个元素。
即使把2个元素散列到有100个单元的表中,仍然有可能发生冲突。
采用线性探测法处理散列时的冲突,当从哈希表删除一个记录时,不应将这个记录的所在位置置空,因为这会影响以后的查找。
在散列检索中,“比较”操作一般也是不可避免的。
若散列表的负载因子α<1,则可避免碰撞的产生。
当采用线性探测冲突解决策略时,非空且有空闲空间的散列表中无论有多少元素,不成功情况下的期望查找次数总是大于成功情况下的期望查找次数。
将 10 个元素散列到 100 000 个单元的哈希表中,一定不会产生冲突。
如果一个问题可以用动态规划算法解决,则总是可以在多项式时间内解决的。
只有当局部最优跟全局最优解一致的时候,贪心法才能给出正确的解。
任何一个递归过程都可以转换成非递归过程。
在活动选择问题(Activity Selection Problem)中,令 S 为活动的集合。以“每次收集最迟开始的活动”为贪心原则,可以正确找到 S 中相互兼容活动的最大规模的子集合。
用贪心法求解部分背包问题,不能肯定得到最优解,有时可以得到近似最优解。
递归实现可以看成是一个先自上而下,后自下而上的过程; 而迭代实现可以看成是一个纯粹自下而上的过程。
长度为的序列有个子序列。(依次任意取舍元素所构成的序列称为子序列)
对n皇后问题,若n为偶数,那么可行解的个数也是偶数。
为提高求解效率,使用回溯法时可同时用约束函数和上界函数来剪去一部分子树。
0-1背包问题的解空间树是一颗排列树。
希尔排序是稳定的算法。
插入排序算法在每一趟都能选取出一个元素放在其最终的位置上。
直接插入排序是不稳定的排序方法。
对N个不同的数据采用冒泡排序进行从大到小的排序,当元素基本有序时交换元素次数肯定最多。
由于希尔排序的最后一趟与直接插入排序过程相同,因此前者一定比后者花费的时间更多。
起泡排序的排序趟数与参加排序的序列原始状态有关。
对于n个记录的集合进行冒泡排序,在最坏情况下需要的时间是。
直接选择排序的时间复杂度为,不受数据初始排列的影响。
内排序的快速排序方法,在任何情况下均可得到最快的排序效果。
当所需排列数据基本有序时,使用快速排序能更快完成排序。
下面的程序段违反了算法的()原则。
执行下面程序段时,执行S语句的频度为()。
下列程序的时间复杂度为()。
求整数n(n>=0)的阶乘的算法如下,其时间复杂度为( )。
设 是描述问题规模的非负整数,下列程序段的时间复杂度是:
下面算法所执行的加法次数( )。
输入:,其中,为正整数
输出:
算法P1和P2时间复杂度的递推方程分别为:
P1:T() = T(/2) + 1, T(1)=1
P2:T() = 2T(/2) + 1, T(1)=1
则下列关于P1和P2两个算法时间复杂度的结论中正确的是( )。
T(n)表示当输入规模为n时的算法效率,以下算法中效率最优的是( )。
下面算法的空间复杂度为 ▁▁▁▁▁。
下列对顺序存储的有序表(长度为 )实现给定操作的算法中,平均时间复杂度为 的是:
在包含 个数据元素的顺序表中,▁▁▁▁▁ 的时间复杂度为 。
线性表L=(a1, a2 ,……,a100 )用一维数组存储。在元素a50之后插入一个新的元素,需要移动元素的个数是( )。
在VC环境下,下面数组定义正确的是( )。
这是一个单选题的样例,分值为1分。
1、从一个长度为n的顺序表中删除第i个元素(1≦i≦n)时,需向前移动( )个元素。
线性表有元素50个,存储在数组A【1..100】中,在第25个元素之后插入一个元素,需要移动元素( )个。
在N个元素的顺序表中,算法的时间复杂度为O(1)的是( )。
1.顺序查找长度为n的线性表的平均查找长度为(C)。
关于表结构说法正确的是()。
顺序查找长度为n的线性表的平均成功的查找长度为_____。
在长度为n的顺序表任意位置插入元素,平均需要移动( )个元素
已知指针ha和hb分别是两个单链表的头指针,下列算法将这两个链表首尾相连在一起,并形成一个循环链表(即ha的最后一个结点链接hb的第一个结点,hb的最后一个结点指向ha),返回ha作为该循环链表的头指针。请将该算法补充完整。
在单链表中,将 s 所指新结点插入到 p 所指结点之后,其语句应该为 ▁▁▁▁▁ 。
在双链表中,将 s 所指新结点插入到 p 所指结点之后,其语句应该为 ▁▁▁▁▁ 。
已知头指针 h 指向一个带头结点的非空单循环链表,结点结构为 data | next,其中 next 是指向直接后继结点的指针,p 是尾指针,q 是临时指针。现要删除该链表的第一个元素,正确的语句序列是:
线性表在 ▁▁▁▁▁ 情况下适合采用链式存储结构。
假设某个带头结点的单链表的头指针为head,则判定该表为空表的条件是( )
在包含 个数据元素的单链表中,▁▁▁▁▁ 的时间复杂度不为 。
若某线性表最常用的操作是在表头进行插入和删除,则利用哪种存储方式最合适?
现有非空双向链表 ,其结点结构为: ,
,prev 是指向直接前驱结点的指针,next 是指向直接后继结点的指针。若要在 中指针 p 所指向的结点(非尾结点)之后插入指针 s 指向的新结点,则在执行了语句序列 s->next = p->next; p->next = s; 后,下列语句序列中还需要执行的是:
已知带头结点的非空单链表 L 的头指针为 h,结点结构为 data | next,其中 next 是指向直接后继结点的指针。现有指针 p 和 q,若 p 指向 L 中非首且非尾的任意一个结点,则执行语句序列 q = p->next; p->next = q->next; q->next = h->next; h->next = q; 的结果是
在作进栈运算时,应先判别栈是否(① );在作退栈运算时应先判别栈是否(② )。当栈中元素为n个,作进栈运算时发生上溢,则说明该栈的最大容量为(③ )。
①: A. 空 B. 满 C. 上溢 D. 下溢
②: A. 空 B. 满 C. 上溢 D. 下溢
③: A. n-1 B. n C. n+1 D. n/2
若栈采用顺序存储方式存储,现两栈共享空间V[1..m],top[i]代表第i个栈( i =1,2)栈顶元素所在的下标,栈1的底在v[1],栈2的底在V[m],则栈满的条件是( )。
在作进栈运算时,应先判别栈是否(① );在作退栈运算时应先判别栈是否(② )。当栈中元素为n个,作进栈运算时发生上溢,则说明该栈的最大容量为(③ )。
①: A. 空 B. 满 C. 上溢 D. 下溢
②: A. 空 B. 满 C. 上溢 D. 下溢
③: A. n-1 B. n C. n+1 D. n/2
若栈采用顺序存储方式存储,现两栈共享空间V[1..m],top[i]代表第i个栈( i =1,2)栈顶(该位置不存储对应栈数据),栈1的底在v[1],栈2的底在V[m],则栈满的条件是( )。
设有一顺序栈S,元素s1,s2,s3,s4,s5,s6依次进栈,如果6个元素出栈的顺序是s2,s3,s4, s6 , s5,s1,则栈的容量至少应该是( )。
元素A,B,C,D依次入栈,出栈无限制,则以下( )是可能的出栈序列。
用S表示入栈操作,X表示出栈操作,若元素入栈的顺序为1234,为了得到1342出栈顺序,相应的S和X的操作串为( )。
给定有限符号集 S , in 和 out 均为 S 中所有元素的任意排列。 对于初始为空的栈 ST, 下列叙述中,正确的是:
检查表达式中的括号是否匹配的问题需要借助________来解决。
设栈S和队列Q的初始状态为空,元素1、2、3、4、5和6依次通过S,每个元素出栈后即进入Q,若6个元素出队的序列是2、6、5、4、3和1,则栈S的容量至少应该是( )
为解决计算机主机与打印机之间速度不匹配问题,通常设置一个打印数据缓冲区,主机将要输出的数据依次写入该缓冲区,而打印机则依次从该缓冲区中取出数据。该缓冲区的逻辑结构应该是?
若已知一队列用单向链表表示,该单向链表的当前状态(含3个对象)是:1->2->3,其中x->y表示x的下一节点是y。此时,如果将对象4入队,然后队列头的对象出队,则单向链表的状态是:
某队列允许在其两端进行入队操作,但仅允许在一端进行出队操作。若元素a、b、c、d、e依次入此队列后再进行出队操作,则不可能得到的出队序列是:
在一个不带头结点的非空链式队列中,假设f和r分别为队头和队尾指针,则插入s所指的结点运算是( )。
最不适合用作链队的链表是()。
现有队列 Q 与栈 S,初始时 Q 中的元素依次是{ 1, 2, 3, 4, 5, 6 }(1在队头),S 为空。若允许下列3种操作:(1)出队并输出出队元素;(2)出队并将出队元素入栈;(3)出栈并输出出栈元素,则不能得到的输出序列是:
栈和队列的共同点是( )。
已知初始为空的队列 Q 的一端仅能进行入队操作,另外一端既能进行入队操作又能进行出队操作。若 Q 的入队序列是 1、2、3、4、5,则不能得到的出队序列是:
若用大小为6的数组来实现循环队列,且当前front和rear的值分别为1和4。当从队列中删除两个元素,再加入三个元素后,front和rear的值分别为( )。
队列的插入在 ▁▁▁▁▁ 进行,删除在 ▁▁▁▁▁ 进行。
完全二叉树顺序存储,结点X的编号为42,则其右孩子结点的编号是( )
完全二叉树顺序存储,结点X的编号为37,则其右孩子结点的编号是( )
完全二叉树顺序存储,结点X的编号为47,则其右孩子结点的编号是( )
完全二叉树顺序存储,结点X的编号为35,则其右孩子结点的编号是( )
完全二叉树顺序存储,结点X的编号为39,则其右孩子结点的编号是( )
完全二叉树顺序存储,结点X的编号为46,则其右孩子结点的编号是( )
完全二叉树顺序存储,结点X的编号为44,则其右孩子结点的编号是( )
完全二叉树顺序存储,结点X的编号为33,则其右孩子结点的编号是( )
深度为k的完全二叉树的第k层至少有( )个结点。
完全二叉树存储在数组A【1..10】中,其元素值为{10,20,30,40,50,60,70,80,90,100},则元素50的双亲是( )。
有18个叶子的哈夫曼树的结点总数为 ( ).
有17个叶子的哈夫曼树的结点总数为 ( ).
有14个叶子的哈夫曼树的结点总数为 ( ).
有21个叶子的哈夫曼树的结点总数为 ( ).
有24个叶子的哈夫曼树的结点总数为 ( ).
若某二叉树有 5 个叶结点,其权值分别为 10、12、16、21、30,则其最小的带权路径长度(WPL)是:
在由 6 个字符组成的字符集 中,各字符出现的频次分别为 3,4,5,6,8,10,为 构造的哈夫曼编码的加权平均长度为:
一颗哈夫曼树共有101个元素,则度为2的结点有( )个。
由元素{3 5 4 2 7}为叶子结点构成的哈夫曼树的带权路径长度WPL为( )。
字母ABCDE的不等长编码不可能是_____。
图的广度优先遍历需要借助的数据结构是
有向图采用邻接矩阵存储,则每列的非零元素个数表示的是
有向图的邻接链表如下,则顶点C的入度为

图的逆邻接表如下所示: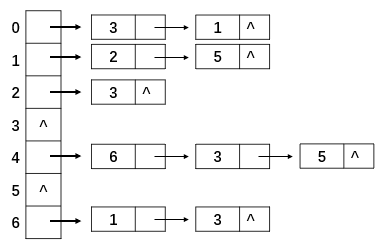
则图应为:
图G如下所示,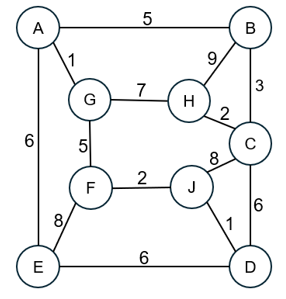
使用Prim(普利姆)算法从顶点C开始寻找 最小生成树 ,选择的第3条边是:
图G如下所示,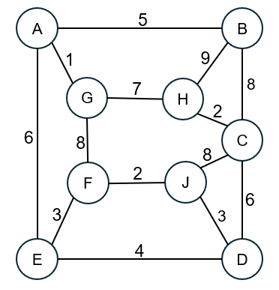
使用Kruskal(克鲁斯卡尔)算法寻找 最小生成树 ,选择的第6条边是:
图G如下所示,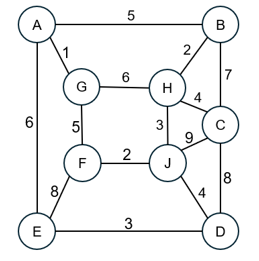
使用迪杰斯特拉(Dijkstra)算法求 顶点C 到其他每个顶点的最短路径(显然,顶点C到自己的最短路径长度为0),则其他顶点中,第3个确定最短路径的是:
一个由n个顶点组成的连通无向图,其边的个数至少为( )。
在有n个顶点的完全有向图中边的数目是( )。
在一个无向图中,所有顶点的度数之和等于所有边数的( )倍。
既希望较快的查找又便于线性表动态变化的查找方法是 ( )
设有一组记录的关键字为{19,14,23,1,68,20,84,27,55,11,10,79},用链地址法构造散列表,散列函数为H(key)=key MOD 13,散列地址为1的链中有( )个记录。
下面关于哈希(Hash,杂凑)查找的说法正确的是( )
关于杂凑查找说法不正确的有几个( )
(1)采用链地址法解决冲突时,查找一个元素的时间是相同的
(2)采用链地址法解决冲突时,若插入规定总是在链首,则插入任一个元素的时间是相同的
(3)用链地址法解决冲突易引起聚集现象
(4)再哈希法不易产生聚集
若线性表(24 13 31 6 15 18 8)采用HASH法进行存储和查找,设哈希函数为H(KEY)=KEY MOD 11,则以下( )是同义词。
散列表(哈希表)采用顺序存储,长度为10,散列函数为 (关键字对7取余),采用线性探测法解决冲突。向空表依次插入8个关键字{ 21, 77, 1, 13, 6, 27, 48, 41 }后,关键字查找成功的平均查找长度(ASLs)为:(四舍五入保留一位小数)
散列表(哈希表)采用顺序存储,长度为10,散列函数为 (关键字对7取余),采用线性探测法解决冲突。向空表依次插入8个关键字{ 21, 77, 13, 6, 27, 48, 41, 12 }后,关键字查找成功的平均查找长度(ASLs)为:(四舍五入保留一位小数)
顺序查找法适合于存储结构为( )的线性表。
在散列存储中,装填因子α的值越大,则( )。
在散列存储中,装填因子α的值越小,则( )。
对n个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为( )
对n个不同的排序码进行冒泡排序,在元素无序的情况下比较的次数最多为( )。
元素{3,50,27,46,44,20}通过冒泡法排序(从小到大),第一趟的结果是( )。
直接插入排序和冒泡排序在初始数据基本有序的情况下,时间复杂性均为。
对一组数据(84,47,25,15,21)排序,数据的排列次序在排序的过程中的变化为:
初始序列 84 47 25 15 21
第一趟排序结果 15 47 25 84 21
第二趟排序结果15 21 25 84 47
第三趟排序结果15 21 25 84 47
则采用的排序是 ( )。
元素比较次数与初始排列次序无关的是排序。
用简单选择排序方法对 n 个元素进行排序时,最坏情况下,比较的次数与移动次数分别是。
插入排序和选择排序是都不稳定。
插入排序时间复杂度大于选择排序时间复杂度。
设有元素(45,27,11,65,3,72,89)采用简单选择排序,则第一趟的结果是
直接插入排序在最好的情况下时间复杂度为( )。
从未排序的序列中顺次取出一个元素与已排序序列中的元素依次进行二分比较,然后将其放在排序序列的合适位置,该排序方法称为排序。
排序方法中,从未排序序列中挑选元素,并将其依次插入已排序序列(初始时为空)的一端的方法称为
在对n个元素进行直接插入排序的过程中,算法的空间复杂度。
在对一组记录(54,38,96,23,15,72,60,45,83)进行直接插入排序时,当把第7个记录60插入到有序表时,为寻找插入位置至少需比较多少次。
在一棵有N 个结点的非平衡二叉树中进行查找,平均时间复杂度的上限(即最坏情况平均时间复杂度)为2 分 。
下面程序段的时间复杂度是2 分 。
下面程序段的时间复杂度是2 分 。
请写出下面程序段的时间复杂度为O(2 分)
void fun(int n)
{
}
试题 B:既约分数
本题总分: 5分
[问题描述]
如果一个分数的分子和分母的最大公约数是 1,这个分数称为既约分数。
例如,, , , 都是既约分数。
请问,有多少个既约分数,分子和分母都是 1 到 2021 之间的整数(包括 1 和 2021)?
[答案提交]
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
2 分
以时间复杂度为例,大 表示法表示算法运行时间的 1 分,
标识一种算法可能有的 1 分 增长率。
其数学定义为:对非负函数 和 ,若存在两个正常数 和 ,
对于任意 ,都有 ,
则称在集合 中,记作:。
以时间复杂度为例,大 表示法表示算法运行时间的 1 分,
标识一种算法可能有的 1 分 增长率。
其数学定义为:对非负函数 和 ,若存在两个正常数 和 ,
对于任意 ,都有 ,
则称 在集合 中,记作:。
【2012统考真题】求整数n(n≥0)的阶乘的算法代码如下,其时间复杂度是 O (2 分)。
int fact(int n){
if(n <= 1) return 1;
return n * fact(n - 1);
}
请问输出结果中sum1=1 分,sum2=1 分。
请用指针法完成数组的输入输出操作
两个长度分别为m、n的有序单链表,在采用二路归并算法产生一个有序单链表时,算法的时间复杂度为2 分。
有一个含有n个元素的线性表,可以采用单链表或双链表存储,其主要的操作是插入和删除第一个元素,最好选择2 分作为存储结构。
某个含有n个元素的线性表可以采用单链表或双链表存储结构,但要求快速删除指定位置的结点,应采用2 分。
在单链表中若在每个结点中增加一个指针域,所含指针指向前驱结点,这样构成的链表中有两个方向不同的链,称为2 分
线性表L=(a1,a2,…,an)用数组表示,假定删除表中任一元素的概率相同,则删除一个元素平均需要移动元素的个数是2 分。
设单链表的结点结构为(data,next),next为指针域,已知指针px指向单链表中data为x的结点,指针py指向data为y的新结点 , 若将结点y插入结点x之后,则需要执行以下语句:1 分;1 分;
对于双向链表,在两个结点之间插入一个新结点需修改的指针共1 分个,单链表为1 分。
在单链表中若在每个结点中增加一个指针域,所含指针指向前驱结点,这样构成的链表中有两个方向不同的链,称为2 分 。
已知last指向单向简单链表的尾结点,将s所指结点加在表尾,将结点插在表尾的语句是:s->next=NULL,1 分,1 分;。
在单向链表中,删除p所指结点的后继结点的链操作为2 分。(不考虑结点的释放)
添加填空按钮:
以下运算实现在链栈上的进栈,请在空白处用请适当句子予以填充。
以下运算实现在链栈上的退栈,请在空白处用请适当句子予以填充。
以下运算实现在链栈上的初始化,请在空白处用请适当句子予以填充。
以下运算实现在链栈上的退栈,请在空白处用请适当句子予以填充。
设栈S和队列Q的初始状态均为空,元素{1, 2, 3, 4, 5, 6, 7}依次进入栈S。若每个元素出栈后立即进入队列Q,且7个元素出队的顺序是{2, 6, 5, 4, 7, 3, 1},则栈S的容量至少是:2 分个元素空间。
a,b,c,d,e,f依次进栈,出栈顺序为b,d,c,a,e,f,那么栈容量至少为2 分。
添加填空按钮:
a,b,c,d,e,f依次进栈,出栈顺序为b,e,d,c,a,f,那么栈容量至少为2 分。
添加填空按钮:
假设栈长M,栈顶指针top==0成立时表示栈空,那么栈满判断条件是2 分。
添加填空按钮:
假设栈长M,栈顶指针top==M成立时表示栈满,那么栈空判断条件是2 分。
添加填空按钮:
栈的运算遵循2 分的原则。
2 分 又称为先进先出的线性表。
顺序队列在实现的时候,通常将数组看成是一个首尾相连的循环队列,这样做的目的是为避免产生2 分 现象。
设栈S和队列Q的初始状态都为空,元素a,b,c,d,e,f依次通过栈S,一个元素出栈后即进入队列,若6个元素出队序列是bedfca,则栈S的容量至少应有能够存放2 分个元素的空间。
数组q[M](M等于6)存储一个循环队,first和last分别指向首尾指针。已知first=2,last=5。当从队列中删除一个元素,再插入两个元素后,first=1 分,last=1 分。
数组q[M]存储一个循环队,first和last分别是首尾指针。当前队中元素个数为(A)
(last-1 分+1 分)%M.
数组q[M]存储一个循环队,first和last分别是首尾指针,如果使元素x进队操作的语句为“q[last]=x, last=(last+1)%M;”那么,判断队满的条件是2 分。
添加填空按钮:
数组q[M]存储一个循环队,first和last分别是首尾指针,如果使元素x进队操作的语句为“q[last]=x, last=(last+1)%M;”那么,元素x出队的语句是2 分。
添加填空按钮:
数组q[M](M等于6)存储一个循环队,first和last分别是首尾指针。已知first和last的当前值分别等于2和4,且q[5]存放的是队尾元素。当从队列中删除两个元素,再插入三个元素后,first的值为1 分,last的值为1 分。
添加填空按钮:
数组q[M](M等于7)存储一个循环队,first和last分别是首尾指针。已知first和last的当前值分别等于1和4,且q[3]存放的是队尾元素。当从队列中删除两个元素,再插入三个元素后,first的值为1 分,last的值为1 分。
添加填空按钮:
已知哈希表长度为 8,哈希函数为 ,采用线性探测法处理冲突。
将下列关键字依次插入到哈希表中,
请写出存入数据后的哈希表。
| 0 | 1 分 |
| 1 | 1 分 |
| 2 | 1 分 |
| 3 | 1 分 |
| 4 | 1 分 |
| 5 | 1 分 |
| 6 | 1 分 |
| 7 | 1 分 |
注:空白处填“-”。
若各关键字的检索概率相同,则平均查找长度为 2 分 (保留1位小数,末位四舍五入)。
已知哈希表长度为 8,哈希函数为 ,采用线性探测法处理冲突。
将下列关键字依次插入到哈希表中,
请写出存入数据后的哈希表。
| 0 | 1 分 |
| 1 | 1 分 |
| 2 | 1 分 |
| 3 | 1 分 |
| 4 | 1 分 |
| 5 | 1 分 |
| 6 | 1 分 |
| 7 | 1 分 |
注:空白处填“-”。
若各关键字的检索概率相同,则平均查找长度为 2 分 (保留1位小数,末位四舍五入)。
在下面的线性表中
若采用顺序搜索算法,则查找元素 50 时,需要比较 2 分 次。
在下面的线性表中
若采用顺序搜索算法,则查找元素 83 时,需要比较 2 分 次。
在下面的线性表中
若采用顺序搜索算法,则查找元素 24 时,需要比较 2 分 次。
在下面的线性表中,
若采用二分查找算法,则查找元素 58 时,需要比较 2 分 次。
在下面的线性表中
若采用顺序查找算法,假设各元素的检索概率相同,则平均查找长度为 2 分。
在下面的线性表中
若采用顺序查找算法,则查找元素 58 时,需要比较 2 分 次。
在下面的线性表中,
若采用二分查找算法,则最大查找长度为 2 分。
在下面的线性表中,
若采用顺序查找算法,则最大查找长度为 2 分。
在下面的线性表中,
若采用二分查找算法,假设各元素的检索概率相同,则平均查找长度为 2 分。
本题目已定义一个 People 类。属性:名字(name)、年龄(age);方法:getName() 获取名字、toString() 输出对象。
现使用链表存储 People 对象。首先,通过输入创建 People 对象并插入到链表;然后,删除指定名字的链表元素。
有一学生类(Student),含有姓名(name)、年龄(age)属性,该类实现Comparable接口,要求重写compareTo方法,实现按照年龄的大小来确定两个学生的大小关系。
在链表中添加3个学生对象,通过Collections类的sort方法对链表中的学生按照年龄升序排序。输入第4个学生对象,并查找他(她)的年龄是否与链表中某个学生的年龄相同。
根据二叉树的先序遍历序列和中序遍历序列,输出它的后序遍历序列。
请将其中的创建方法 补充完整。
方法 定义:
其中pre是先序序列,i是对应子树在先序序列的起始位置,
in是中序序列,j是对应子树在中序序列的起始位置,
n是对应子树的元素个数。
裁判测试程序样例:
输入样例:
输入有两行,第1行是先序遍历序列,第2行是中序遍历序列。
其中元素类型为字符型。
例如:
输出样例:
输出结果有1行,是对应二叉树的后序遍历序列。
其中每个元素后有一个空格,用于分隔。例如:
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 空 | ||||
用先序序列和中序序列创建一棵二叉树,输出它的高度。
要求 :
(1)编写先序序列和中序序列创建二叉树的方法
(2)求二叉树高度的方法
函数接口定义:
裁判测试程序样例:
输入样例:
输入有两行,第1行是先序遍历序列,第2行是中序遍历序列。
其中元素类型为字符型。
例如:
输出样例:
输出二叉树的高度。
例如:
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 空 | ||||
根据二叉树的后序遍历序列和中序遍历序列,用括号表示法输出二叉树。 请将其中的创建方法 补充完整。
函数接口定义:
``Java
private BTNode CreateBT21(String post,int i, String in,int j,int n){
}
private void toString1(BTNode root) {
}
输入样例1:
输入有两行,第1行是后序遍历序列,第2行是中序遍历序列。 其中元素类型为字符型。 例如:
输出样例1:
输出结果有1行,是对应二叉树的括号表示法。
例如:
输入样例2:
输出样例2:
输入样例3:
输出样例3:
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 空 | ||||
请设计一个能够将有序顺序表LA,LB进行合并的算法,要求合并后的顺序表LC依然有序。
例如:
LA的元素 1 3 5 7
LB的元素 2 4
LC的元素 1 2 3 4 5 7
其中,LA和LB的长度不超过1000,当中的元素为非递减排序。
输入格式:
第一行输入LA的长度
第二行输入LA的元素
第三行输入LB的长度
第四行输入LB的元素
输出格式:
输入合并后顺序表中各元素的值,值之间用一个空格间隔。
输入样例1:
输出样例1:
输入样例2:
输出样例2:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读取LA的长度和元素
int lengthA = scanner.nextInt();
int[] LA = new int[lengthA];
for (int i = 0; i < lengthA; i++) {
LA[i] = scanner.nextInt();
}
// 读取LB的长度和元素
int lengthB = scanner.nextInt();
int[] LB = new int[lengthB];
for (int i = 0; i < lengthB; i++) {
LB[i] = scanner.nextInt();
}
// 合并两个有序数组
int[] LC = mergeSortedArrays(LA, lengthA, LB, lengthB);
// 输出合并后的数组
for (int i = 0; i < LC.length; i++) {
System.out.print(LC[i] + " ");
}
scanner.close();
}
public static int[] mergeSortedArrays(int[] LA, int lengthA, int[] LB, int lengthB) {
int[] LC = new int[lengthA + lengthB]; // 创建一个足够大的数组来存储合并后的结果
int i = 0, j = 0, k = 0; // i, j为LA和LB的索引,k为LC的索引
// 遍历两个数组,将较小的元素依次放入LC中
while (i < lengthA && j < lengthB) {
if (LA[i] <= LB[j]) {
LC[k++] = LA[i++];
} else {
LC[k++] = LB[j++];
}
}
// 如果LA还有剩余元素,将它们添加到LC
while (i < lengthA) {
LC[k++] = LA[i++];
}
// 如果LB还有剩余元素,将它们添加到LC
while (j < lengthB) {
LC[k++] = LB[j++];
}
return LC;
}
}无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 1 | 答案正确 | 3 | 119.00 ms | 19348 KB |
| 2 | 答案正确 | 3 | 123.00 ms | 19812 KB |
| 3 | 答案正确 | 4 | 122.00 ms | 20048 KB |
请设计一个算法,在有序顺序表L中插入元素x,使得表依然有序,并输出新增元素后的表数据。
例如:
L的元素 1 3 5 7
插入新元素 4
输出 1 3 4 5 7
其中,L的长度不超过1000,当中的元素为非递减排序。
输入格式:
第一行输入L的长度
第二行输入L的元素
第三行输入要插入的元素x的值
输出格式:
输入插入元素后顺序表中各元素的值,值之间用一个空格间隔。
输入样例:
输出样例:
import java.util.Scanner;
import java.util.TreeSet;
public class Main{
public static void main(String[] args){
Scanner scanner = new Scanner(System.in);
// 读取数组长度
int n = scanner.nextInt();
TreeSet<Integer> tset = new TreeSet<>();
for (int i = 0; i < n; i++) {
int t = scanner.nextInt();
tset.add(t);
}
int t = scanner.nextInt();
tset.add(t);
for (int m:tset) {
System.out.print(m+" ");
}
}
}无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 1 | 答案正确 | 3 | 123.00 ms | 19380 KB |
| 2 | 答案正确 | 4 | 126.00 ms | 19368 KB |
| 3 | 答案正确 | 3 | 126.00 ms | 19536 KB |
本题目要求读入M(最大为10)行N(最大为15)列个元素,找出其中最大的元素,并输出其行列值。
输入格式:
输入在第一行中给出行数m和列数n。
接下来输入m*n个整数。
输出格式:
输出最大值的行号,列号,值。
输入样例:
输出样例:
最大值为1行2列的6
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读取行数和列数
int m = scanner.nextInt();
int n = scanner.nextInt();
// 初始化最大值及其位置
int maxValue = Integer.MIN_VALUE;
int maxRow = -1;
int maxCol = -1;
// 遍历二维数组
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
int currentValue = scanner.nextInt();
if (currentValue > maxValue) {
maxValue = currentValue;
maxRow = i; // 行号从1开始计数
maxCol = j; // 列号从1开始计数
}
}
}
// 输出结果
System.out.printf("%d,%d,%d", maxRow, maxCol, maxValue);
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| test | 答案正确 | 4 | 121.00 ms | 19416 KB |
| test2 | 答案正确 | 3 | 122.00 ms | 20736 KB |
| test3 | 答案正确 | 3 | 138.00 ms | 20484 KB |
一个数组,初始数组为空,实现以下两种操作:
1. 输入1 x y,将x插入在元素y的右边。保证此时数组中没有元素等于x,且数组中存在一个y。特殊的,如果将x插入在数组的最左边,则y=0
2. 输入2 x,将元素x删除。
请你在所有操作后输出整个数组。
输入格式:
第一行输入一个正整数q,代表操作次数。
接下来的q行,每行输入两个整数2 x或者三个整数1 x y,代表一次操作。操作含义如题目说明。
1≤q≤2×10^5, 1≤x≤10^9, 0≤y≤10^9
输出格式:
第一行输出一个整数n,代表最终数组的大小。
第二行输出n个正整数,代表最终的数组。
输入样例:
输出样例:
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读取操作次数
int q = scanner.nextInt();
// 使用ArrayList来模拟数组操作
List<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < q; i++) {
int op = scanner.nextInt();
if (op == 1) {
int x = scanner.nextInt();
int y = scanner.nextInt();
// 找到y的索引,如果不存在y则无法插入(但题目保证y存在)
int index = arrayList.indexOf(y);
// 如果y是0,则插入到最左边
if (y == 0) {
arrayList.add(0, x);
} else {
// 否则插入到y的右边
arrayList.add(index + 1, x);
}
} else if (op == 2) {
int x = scanner.nextInt();
arrayList.remove(Integer.valueOf(x));
}
}
// 输出结果
System.out.println(arrayList.size());
for (int num : arrayList) {
System.out.print(num + " ");
}
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| test1 | 答案正确 | 5 | 131.00 ms | 20920 KB |
| test2 | 答案正确 | 5 | 126.00 ms | 20000 KB |
根据输入的操作命令,操作队列:1 入队、2 出队并输出、3 计算队中元素个数并输出。1≤N≤50。
输入格式:
第一行一个数字 N。 接下来 N 行,每行第一个数字为操作命令:1入队、2 出队并输出、3 计算队中元素个数并输出。
输出格式:
若干行每行显示一个 2 或 3 命令的输出结果。注意:2.出队命令可能会出现空队出队(下溢),请输出“no”,并退出。
输入样例:
在这里给出一组输入。例如:
输出样例:
在这里给出相应的输出。例如:
import java.util.ArrayList;
import java.util.Scanner;
public class Main{
public static void main(String[] arge){
Scanner in=new Scanner(System.in);
int n=in.nextInt();
ArrayList<Integer> list=new ArrayList<Integer>();
ArrayList<Integer> lis=new ArrayList<Integer>();
for(int i=1;i<=n;i++){
int x=in.nextInt();
if(x==1){
int y=in.nextInt();
list.add(y);
}
else if(x==2){
if(list.size()>0){
lis.add(list.get(0));
list.remove(0);
}
else{
for(int k:lis)
System.out.println(k);
System.out.println("no");
return;
}
}
else{
lis.add(list.size());
}
}
for(int k:lis)
System.out.println(k);
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 1 | 答案正确 | 5 | 107.00 ms | 19456 KB |
| 2 | 答案正确 | 5 | 110.00 ms | 19884 KB |
将两个递增有序的顺序表合并为一个递增有序的顺序表,要求表中不能存在重复的数据
输入格式:
共两行,每一行为一个有序表的数据。
输出格式:
对每一组输入,在一行中输出合并后有序表的数据(最后不得有空格输出)。
输入样例:
在这里给出一组输入。例如:
输出样例:
在这里给出相应的输出。例如:
import java.util.Scanner;
import java.util.Set;
import java.util.TreeSet;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读取输入的两个有序表
String[] list1Str = scanner.nextLine().split(" ");
String[] list2Str = scanner.nextLine().split(" ");
// 使用TreeSet来合并两个有序表并去除重复
Set<Integer> mergedSet = new TreeSet<>();
for (String numStr : list1Str) {
mergedSet.add(Integer.parseInt(numStr));
}
for (String numStr : list2Str) {
mergedSet.add(Integer.parseInt(numStr));
}
// 输出合并后的有序表数据
for (int i= 0;i < mergedSet.size();i++) {
if(i < mergedSet.size()-1)
System.out.print(mergedSet.toArray()[i] + " ");
else
System.out.print(mergedSet.toArray()[i]);
}
}
}
import java.util.Scanner;
import java.util.Set;
import java.util.TreeSet;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读取输入的两个有序表
String[] list1Str = scanner.nextLine().split(" ");
String[] list2Str = scanner.nextLine().split(" ");
// 使用TreeSet来合并两个有序表并去除重复
Set<Integer> mergedSet = new TreeSet<>();
for (String numStr : list1Str) {
mergedSet.add(Integer.parseInt(numStr));
}
for (String numStr : list2Str) {
mergedSet.add(Integer.parseInt(numStr));
}
// 输出合并后的有序表数据
for (int i= 0;i < mergedSet.size();i++) {
if(i < mergedSet.size()-1)
System.out.print(mergedSet.toArray()[i] + " ");
else
System.out.print(mergedSet.toArray()[i]);
}
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| basic | 答案正确 | 2 | 111.00 ms | 19156 KB |
| test2 | 答案正确 | 2 | 114.00 ms | 19504 KB |
| bignum | 答案正确 | 3 | 115.00 ms | 19360 KB |
| repeat2 | 答案正确 | 3 | 114.00 ms | 19448 KB |
你刚从滑铁卢搬到了一个大城市,这里的人们讲一种难以理解的外语方言。幸运的是,你有一本字典来帮助你理解它们。
输入格式:
输入第一行是正整数N和M,后面是N行字典条目(最多10000条),然后是M行要翻译的外语单词(最多10000个)。每一个字典条目都包含一个英语单词,后面跟着一个空格和一个外语单词。
输入中的每个单词都由最多10个小写字母组成。
输出格式:
输出翻译后的英文单词,每行一个单词。非词典中的外来词汇输出“eh”。
输入样例:
输出样例:
import java.util.HashMap;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int N = scanner.nextInt();
int M = scanner.nextInt();
scanner.nextLine();
HashMap<String, String> dictionary = new HashMap<>();
for (int i = 0; i < N; i++) {
String english = scanner.next();
String foreign = scanner.next();
dictionary.put(foreign, english);
scanner.nextLine();
}
for (int i = 0; i < M; i++) {
String foreignWord = scanner.next();
if (dictionary.containsKey(foreignWord)) {
System.out.println(dictionary.get(foreignWord));
} else {
System.out.println("eh");
}
}
scanner.close();
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| D1 | 答案正确 | 5 | 232.00 ms | 23868 KB |
| D2 | 答案正确 | 5 | 595.00 ms | 41936 KB |
有一个数据字典,里面存有n个数字(n<=100000),小明现在接到一个任务,这项任务看起来非常简单——给定m个数字,分别查询这m个数字是否出现在字典之中;但是考虑到数据量的问题,小明找到了善于编程的你,希望你可以帮他解决这个问题。
输入格式:
输入数据只有一组!
第一行包含两个整数n m,分别代表字典中数字的个数和要查询的数字的个数。
接着n行代表字典中的n个数字。
最后m表示要查询的数字。
输出格式:
如果某个数字存在,则输出YES,否则输出NO
输入样例:
在这里给出一组输入。例如:
输出样例:
在这里给出相应的输出。例如:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashSet;
import java.util.Set;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
// 读取n和m
String[] nm = reader.readLine().split(" ");
int n = Integer.parseInt(nm[0]);
int m = Integer.parseInt(nm[1]);
// 初始化HashSet来存储字典中的数字
Set<Integer> dictionary = new HashSet<>();
// 读取字典中的n个数字并添加到HashSet中
for (int i = 0; i < n; i++) {
int number = Integer.parseInt(reader.readLine().trim());
dictionary.add(number);
}
// 读取要查询的m个数字,并检查它们是否在HashSet中
for (int i = 0; i < m; i++) {
int query = Integer.parseInt(reader.readLine().trim());
if (dictionary.contains(query)) {
System.out.println("YES");
} else {
System.out.println("NO");
}
}
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| test1 | 答案正确 | 4 | 46.00 ms | 17636 KB |
| test2 | 答案正确 | 3 | 46.00 ms | 17720 KB |
| test3 | 答案正确 | 3 | 47.00 ms | 17780 KB |
给你一个序列,有N个整数(int以内),判断一个数在这个序列中出现几次。
输入格式:
多组输入,输入到文件结尾;首先输入一个n,然后输入n个整数。再输入一个m,代表查询的个数 ,然后输入m个数(int以内)。n,m <= 100000;
输出格式:
对应每一次查询,输出这个数在序列中出现几次。
输入样例:
在这里给出一组输入。例如:
输出样例:
在这里给出相应的输出。例如:
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
// 读取序列长度n
int n = Integer.parseInt(reader.readLine());
// 使用HashMap存储序列中每个数及其出现次数
Map<Integer, Integer> countMap = new HashMap<>();
// 读取序列中的n个整数并更新HashMap
StringTokenizer tokenizer = new StringTokenizer(reader.readLine());
for (int i = 0; i < n; i++) {
int num = Integer.parseInt(tokenizer.nextToken());
countMap.put(num, countMap.getOrDefault(num, 0) + 1);
}
// 读取查询数量m
int m = Integer.parseInt(reader.readLine());
// 处理每个查询并输出结果
tokenizer = new StringTokenizer(reader.readLine());
for (int i = 0; i < m; i++) {
int query = Integer.parseInt(tokenizer.nextToken());
System.out.println(countMap.getOrDefault(query, 0));
}
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| test1 | 答案正确 | 3 | 46.00 ms | 17804 KB |
| test2 | 答案正确 | 3 | 46.00 ms | 17688 KB |
| test3 | 答案正确 | 4 | 47.00 ms | 17744 KB |
给定一个字符串,找出并输出第一个在字符串中只出现一次的字符。如果所有字符都出现多次,则输出"No unique character"。
输入格式:
给出一个任意字符串。
输出格式:
输出第一个在字符串中只出现一次的字符,如果没有则输出“No unique character”。
输入样例1:
输出样例2:
输入样例2:
输出样例2:
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String input = scanner.nextLine();
scanner.close();
Map<Character, Integer> countMap = new HashMap<>();
for (char c : input.toCharArray()) {
countMap.put(c, countMap.getOrDefault(c, 0) + 1);
}
for (char c : input.toCharArray()) {
if (countMap.get(c) == 1) {
System.out.println(c);
return;
}
}
System.out.println("No unique character");
}
}
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String input = scanner.nextLine();
scanner.close();
Map<Character, Integer> countMap = new HashMap<>();
for (char c : input.toCharArray()) {
countMap.put(c, countMap.getOrDefault(c, 0) + 1);
}
for (char c : input.toCharArray()) {
if (countMap.get(c) == 1) {
System.out.println(c);
return;
}
}
System.out.println("No unique character");
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| test3 | 答案正确 | 4 | 108.00 ms | 19644 KB |
| notest | 答案正确 | 3 | 100.00 ms | 19020 KB |
| normaltest | 答案正确 | 3 | 103.00 ms | 19504 KB |
古人说过,相逢便是缘。十年修得同船渡,百年修得共枕眠,是缘分;同年同月同日同时出生的人能够碰到一起也是缘分;本题目是从众多已知生日信息中,求出同年同月同日生的最大人数及其出生日期。
输入格式:
在第一行中输入n,表示有n个出生日期,接下来的n行,每行输入一个出生日期,格式yyyy-mm-dd
输出格式:
第一行输出同年同月同日生的最大人数
第二行以后,每行按日期升序输出一个满足同年同月同日生最大人数的日期。
输入样例:
在这里给出一组输入。例如:
输出样例:
上述出生日期中,19820105出现了3次,20031105也出现了3次,先输出最大次数3,然后按日期升序输出各个日期
import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
// 使用BufferedReader提高输入速度
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
// 使用HashMap统计每个日期出现的次数,初始容量设为n以减少扩容
HashMap<String, Integer> dateCount = new HashMap<>(n);
for (int i = 0; i < n; i++) {
String date = br.readLine().trim();
// 手动去除横杠,比正则表达式更快
date = removeHyphens(date);
Integer count = dateCount.get(date);
dateCount.put(date, count == null ? 1 : count + 1);
}
br.close();
// 找出最大出现次数
int maxCount = 0;
for (int count : dateCount.values()) {
if (count > maxCount) {
maxCount = count;
}
}
// 收集所有出现次数等于最大次数的日期
ArrayList<String> maxDates = new ArrayList<>();
for (Map.Entry<String, Integer> entry : dateCount.entrySet()) {
if (entry.getValue() == maxCount) {
maxDates.add(entry.getKey());
}
}
// 按日期升序排序
Collections.sort(maxDates);
// 使用PrintWriter提高输出速度
PrintWriter pw = new PrintWriter(System.out);
pw.println(maxCount);
for (String date : maxDates) {
pw.println(date);
}
pw.flush();
pw.close();
}
/**
* 手动去除日期字符串中的横杠,比正则表达式replaceAll更快
*/
private static String removeHyphens(String date) {
StringBuilder sb = new StringBuilder(8);
for (int i = 0; i < date.length(); i++) {
char c = date.charAt(i);
if (c != '-') {
sb.append(c);
}
}
return sb.toString();
}
}import java.io.*;
import java.util.*;
public class Main {
public static void main(String[] args) throws IOException {
// 使用BufferedReader提高输入速度
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
// 使用HashMap统计每个日期出现的次数,初始容量设为n以减少扩容
HashMap<String, Integer> dateCount = new HashMap<>(n);
for (int i = 0; i < n; i++) {
String date = br.readLine().trim();
// 手动去除横杠,比正则表达式更快
date = removeHyphens(date);
Integer count = dateCount.get(date);
dateCount.put(date, count == null ? 1 : count + 1);
}
br.close();
// 找出最大出现次数
int maxCount = 0;
for (int count : dateCount.values()) {
if (count > maxCount) {
maxCount = count;
}
}
// 收集所有出现次数等于最大次数的日期
ArrayList<String> maxDates = new ArrayList<>();
for (Map.Entry<String, Integer> entry : dateCount.entrySet()) {
if (entry.getValue() == maxCount) {
maxDates.add(entry.getKey());
}
}
// 按日期升序排序
Collections.sort(maxDates);
// 使用PrintWriter提高输出速度
PrintWriter pw = new PrintWriter(System.out);
pw.println(maxCount);
for (String date : maxDates) {
pw.println(date);
}
pw.flush();
pw.close();
}
/**
* 手动去除日期字符串中的横杠,比正则表达式replaceAll更快
*/
private static String removeHyphens(String date) {
StringBuilder sb = new StringBuilder(8);
for (int i = 0; i < date.length(); i++) {
char c = date.charAt(i);
if (c != '-') {
sb.append(c);
}
}
return sb.toString();
}
}无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| oncedate | 答案正确 | 5 | 44.00 ms | 17872 KB |
| samedate | 答案正确 | 5 | 46.00 ms | 17980 KB |
给定一个长度为N的序列(升序),然后将整数M插入序列,插入后保证序列为升序序列,将插入M后的序列输出。
输入格式:
输入整数N,接着输入长度为N的序列(升序)。以及待插入的整数M。
输出格式:
输出插入M后的序列,末尾没有空格。
输入样例:
输出样例:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int N = scanner.nextInt();
scanner.nextLine();
int[] sequence = new int[N];
for (int i = 0; i < N; i++) {
sequence[i] = scanner.nextInt();
}
int M = scanner.nextInt();
int insertIndex = 0;
while (insertIndex < N && sequence[insertIndex] < M) {
insertIndex++;
}
int[] newSequence = new int[N + 1];
System.arraycopy(sequence, 0, newSequence, 0, insertIndex);
newSequence[insertIndex] = M;
if (insertIndex < N) {
System.arraycopy(sequence, insertIndex, newSequence, insertIndex + 1, N - insertIndex);
}
for (int i = 0; i < newSequence.length; i++) {
System.out.print(newSequence[i] + (i < newSequence.length - 1 ? " " : ""));
}
scanner.close();
}
}无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| insert1 | 答案正确 | 1 | 141.00 ms | 21196 KB |
| insert2 | 答案正确 | 1 | 145.00 ms | 20064 KB |
| insert3 | 答案正确 | 1 | 145.00 ms | 21228 KB |
| insert4 | 答案正确 | 1 | 143.00 ms | 21084 KB |
| insert5 | 答案正确 | 1 | 148.00 ms | 19960 KB |
| insert6 | 答案正确 | 1 | 140.00 ms | 19604 KB |
| insert7 | 答案正确 | 1 | 150.00 ms | 21308 KB |
| insert8 | 答案正确 | 1 | 139.00 ms | 19392 KB |
| insert9 | 答案正确 | 1 | 151.00 ms | 20976 KB |
| insert10 | 答案正确 | 1 | 148.00 ms | 21324 KB |
本题要求编写程序,输入若干英文单词,对这些单词按长度从小到大排序后输出。如果长度相同,按照输入的顺序不变。
输入格式:
输入为若干英文单词,每行一个,以#作为输入结束标志。其中英文单词总数不超过20个,英文单词为长度小于10的仅由小写英文字母组成的字符串。
输出格式:
输出为排序后的结果,每个单词后面都额外输出一个空格。
输入样例:
在这里给出一组输入。例如:
输出样例:
在这里给出相应的输出。例如:
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
ArrayList<String> words = new ArrayList<>();
String word;
while (!(word = scanner.nextLine()).equals("#")) {
words.add(word);
}
Collections.sort(words, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int lengthDiff = Integer.compare(o1.length(), o2.length());
return lengthDiff;
}
});
for (String w : words) {
System.out.print(w + " ");
}
scanner.close();
}
}无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 0 | 答案正确 | 3 | 107.00 ms | 19552 KB |
| 1 | 答案正确 | 3 | 110.00 ms | 19572 KB |
| 2 | 答案正确 | 4 | 105.00 ms | 19516 KB |
某战术指挥中心需将 K 个作战单元按战场态势评估值进行序列整合,采用逐次推进的队列编排方式,每次将下一个作战单元插入到已编排队列的恰当位置。请输出前三阶段编排后的队列状态。
输入格式
输入不超过 100 的正整数 K 和 K 个战场态势评估值(空格分隔)。
输出格式
输出三行,每行表示一个阶段编排后的队列状态,数据间用一个空格分隔。最后一个元素后也需保留空格。
输入样例:
输出样例:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int[] nums = new int[n];
for (int i = 0; i < n; i++) {
nums[i] = in.nextInt();
}
for (int i = 1; i < n; i++) {
int temp = nums[i];
int j;
for (j = i - 1; j >= 0 && nums[j] > temp; j--) {
nums[j + 1] = nums[j];
}
nums[j + 1] = temp;
if (i == 1) {
for (int k = 0; k < n; k++) {
System.out.print(nums[k] + " ");
}
System.out.println();
} else if (i == 2) {
for (int k = 0; k < n; k++) {
System.out.print(nums[k] + " ");
}
System.out.println();
} else if (i == 3) {
for (int k = 0; k < n; k++) {
System.out.print(nums[k] + " ");
}
System.out.println();
}
}
}
}无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| test1 | 答案正确 | 3 | 129.00 ms | 19420 KB |
| test2 | 答案正确 | 4 | 158.00 ms | 20304 KB |
| test3 | 答案正确 | 3 | 149.00 ms | 20932 KB |
将从键盘输入的n个整数进行由小到大排序(不限排序方法)
。
输入格式:
输入在第1行中给出n(1≤n≤100),在第2行中给出n个待排序的整数,数字间以空格分隔。
输出格式:
输出排序后的结果,用空格分隔(最后一个数据后也有一个空格)。
输入样例:
输出样例:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt(); // 读取整数n
int[] array = new int[n];
// 读取n个整数
for (int i = 0; i < n; i++) {
array[i] = scanner.nextInt();
}
// 冒泡排序
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (array[j] > array[j + 1]) {
// 交换array[j]和array[j+1]
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
// 输出排序后的结果
for (int i = 0; i < n; i++) {
System.out.print(array[i] + " ");
}
scanner.close();
}
}无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 0 | 答案正确 | 3 | 122.00 ms | 20232 KB |
| 1 | 答案正确 | 3 | 121.00 ms | 19824 KB |
| 2 | 答案正确 | 4 | 132.00 ms | 20820 KB |
描述
输入一行单词序列,相邻单词之间由1个或多个空格间隔,请按照字典序输出这些单词,要求重复的单词只输出一次。(区分大小写)
输入
一行单词序列,最少1个单词,最多100个单词,每个单词长度不超过50,单词之间用至少1个空格间隔。数据不含除字母、空格外的其他字符。
输出
按字典序输出这些单词,重复的单词只输出一次。
样例输入
样例输出
题目来源
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读取一行输入
String input = scanner.nextLine();
// 使用正则表达式分割单词,处理多个空格的情况
String[] words = input.split("\\s+");
// 使用TreeSet自动去重并按字典序排序
Set<String> wordSet = new TreeSet<>(Arrays.asList(words));
// 输出结果
for (String word : wordSet) {
System.out.println(word);
}
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 0 | 答案正确 | 3 | 108.00 ms | 19196 KB |
| 1 | 答案正确 | 3 | 107.00 ms | 19452 KB |
| 2 | 答案正确 | 4 | 108.00 ms | 19532 KB |

编个题面先:
小明是个爱学习的好孩子,上课的时候老师布置了这么一个作业题:
根据一张由N个正整数组成的数表,两两相加得到新数(共有个),然后将新数按照非递减排序。
举个例子呢就是:如果数表里包含有4个数1,4,3,9,那么正确答案就是4,5,7,10,12,13。
请你编程帮助小明完成这道题吧!
输入格式:
数据有两行,第1行是一个整数N(1<N≤100),表示数表中的整数个数;
第2行是数表中的N个整数(0≤整数≤5000),相邻整数间以一个空格分隔。
输入的N个整数确保不重复。
输出格式:
输出一组按照升序排列的整数的和,相邻整数之间以一个空格分隔。
输入样例:
在这里给出一组输入。例如:
输出样例:
在这里给出相应的输出。例如:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int[] array = new int[n];
for (int i = 0; i < n; i ++) {
array[i] = scanner.nextInt();
}
int[] sumArray = sumArray(array);
int[] sortArray = sortArray(sumArray);
printArray(sortArray);
}
public static int[] sumArray(int[] array) {
int n = array.length;
if (n != 1) {
int[] sumArray = new int[n * (n - 1) / 2];
int count = 0;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
sumArray[count] = array[i] + array[j];
count++;
}
}
return sumArray;
} else {
return array;
}
}
public static int[] sortArray(int[] array) {
for (int i = 0; i < array.length; i ++) {
for (int j = 0; j < array.length - 1 - i; j ++) {
if (array[j] > array[j + 1]) {
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
return array;
}
public static void printArray(int[] array) {
for (int i = 0; i < array.length - 1; i ++) {
System.out.print(array[i] + " ");
}
System.out.print(array[array.length - 1]);
}
}无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 0 | 答案正确 | 2 | 115.00 ms | 19516 KB |
| 1 | 答案正确 | 4 | 122.00 ms | 20872 KB |
| 2 | 答案正确 | 4 | 247.00 ms | 21892 KB |
本题要求从键盘读入n个整数,对这些数做选择排序。输出选择排序每一步的结果和最终结果。
输入格式:
输入的第一行是一个正整数n,表示 在第二行中会有n个整数。
输出格式:
输出选择排序每一步的结果和最终结果。
输入样例:
在这里给出一组输入。例如:
输出样例:
在这里给出相应的输出。例如:
注意:
输出的冒号 : 是英文输入法下的符号,冒号后有一个空格。每个整数后有一个空格。
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = scanner.nextInt();
}
selectionSort(arr);
}
public static void selectionSort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n - 1; i++) {
int minIndex = i;
for (int j = i + 1; j < n; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
System.out.print("step " + (i + 1) + ": ");
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
System.out.print("sorted array: ");
for (int num : arr) {
System.out.print(num + " ");
}
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 1 | 答案正确 | 1 | 115.00 ms | 19556 KB |
| 2 | 答案正确 | 1 | 113.00 ms | 19328 KB |
| 3 | 答案正确 | 2 | 128.00 ms | 20484 KB |
| 4 | 答案正确 | 2 | 135.00 ms | 20748 KB |
| 5 | 答案正确 | 2 | 119.00 ms | 19548 KB |
| 6 | 答案正确 | 2 | 122.00 ms | 19948 KB |
假设学生的基本信息包括学号、姓名、三门课程成绩以及个人平均成绩,定义一个能够表示学生信息的结构类型。输入n(n<50)个学生的成绩信息,按照学生的个人平均分从高到低输出他们的信息。
注意:
1)平均分出现相同的分数时按学号从小到大进行排序输出。
2)平均分以四舍五入取整数保存。
输入格式:
输入一个正整数n(n<50),下面n行输入n个学生的信息,包括:学号、姓名、三门课程成绩(整数)。
输出格式:
输出从高到低排序后的学生信息,包括:学号、姓名、三门课程成绩、平均分(整数)
输入样例:
输出样例:
import java.util.Arrays;
import java.util.Comparator;
import java.util.Scanner;
class Student {
int id;
String name;
int score1;
int score2;
int score3;
int average;
public Student(int id, String name, int score1, int score2, int score3) {
this.id = id;
this.name = name;
this.score1 = score1;
this.score2 = score2;
this.score3 = score3;
this.average = (int) Math.round((score1 + score2 + score3) / 3.0);
}
@Override
public String toString() {
return id + " " + name + " " + score1 + " " + score2 + " " + score3 + " " + average;
}
}
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
Student[] students = new Student[n];
for (int i = 0; i < n; i++) {
int id = scanner.nextInt();
String name = scanner.next();
int score1 = scanner.nextInt();
int score2 = scanner.nextInt();
int score3 = scanner.nextInt();
students[i] = new Student(id, name, score1, score2, score3);
}
Arrays.sort(students, new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
if (s2.average != s1.average) {
return s2.average - s1.average;
} else {
return s1.id - s2.id;
}
}
});
for (Student student : students) {
System.out.println(student);
}
scanner.close();
}
}
无| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 0 | 答案正确 | 8 | 163.00 ms | 22080 KB |
| 1 | 答案正确 | 1 | 154.00 ms | 21724 KB |
| 2 | 答案正确 | 1 | 167.00 ms | 21932 KB |